Lisa and I drove into the city last Wednesday to attend the San Francisco SQL Server User Group meeting, to see a presentation of Microsoft’s latest Data Mining tools. It was a great presentation, very enlightening.
I confess, I’ve always been under a misconception about data mining. For reasons I’ll explain below, I’ve had a bias that “data mining” was all about exploring your data and looking for unexpected trends and relationships that perhaps could then be leveraged.
However, at the user group presentation, as William Brown took us through a data mining exercise, several things became clear to me:
In Data Mining projects, the following axioms are important:
- Know what you’re looking for
- Know how to recognize it when you’ve found it
William started with the following goal: “Of my database of customers who haven’t purchased a bicycle, which of them are likely to buy one?”
He then used the Microsoft toolset to create a “sieve” through which he could pour the customer database and build a collection of likely bicycle purchasers.
This was possible because he started with a table of customers known to be bicycle purchasers, and used a subset of it to effectively “train” the sieve to identify rows with similar properties. He also used the remainder of the known data set to test the sieve’s effectiveness.
This is almost the exact opposite of what I had presumed “Data Mining” was all about, but I stand corrected: “Data Mining” is an excellent description of the process.
You go into the project knowing what it is you want to find, and you have a test that can be used to prove if you are successful.
Digression: Arthur Ransome’s Pigeon Post
In the book Pigeon Post by Arthur Ransome, a team of child explorers decide to go prospecting for gold on the local hills. They base this decision on an old rumor of a lost gold seam up in the hills. Adventures ensue, of course. It’s a great book, with detailed descriptions of the prospecting, ore crushing, smelting, and charcoal burning processes. After an unsuccessful attempt to melt the gold dust into a nugget – it just oxides into a black lump – they know that just finding gold-colored ore isn’t enough: They need a test to prove the result to their uncle, Captain Flint, who has given up on fruitless treasure hunts:
“It probably wasn’t gold at all,” said Susan. “We ought to have made sure.”
Dick looked up suddenly. “There is one way we could,” he said. “We could try with aqua regia. You know, a chemical test. The book says gold dissolves in aqua regia. If it does, we’d know for sure.”
More ore is extracted, and later on Dick performs the test, working in Captain Flint’s workshop laboratory.
Dick’s tests show that the ore does indeed dissolve in aqua regia (a mixture of two strong acids), but his joy is short-lived when Captain Flint returns and reviews the results:

“What’s this? Chemistry?” asked Captain Flint.
“Gold,” said Dick.
“Gold? Don’t you go and get interested in the wretched stuff. I’ve sworn off. Had quite enough wasting time… What have you got in that test tube?”
“Aqua regia,” said Dick. “And gold dust. And it’s gone all right. Dissolved! Gold in the aqua regia. I was just a bit afraid it might not be gold, after all.”
“But, my dear chap,” said Captain Flint. “Aqua regia will dissolve almost anything. The point about gold is that it won’t dissolve in anything else.”
Captain Flint examines the ore and, using his knowledge of the geology of the surrounding hills, comes up with a better test to determine what, exactly, the prospectors have found.
Captain Flint’s test reveals the ore to be copper pyrites, which in its way, turns out to be quite as good a discovery as gold would have been, and the adventure is a success after all.
There’s several insights we can pull from this story:
- Choosing an appropriate “test for success” is critical.
- Domain knowledge is very important, and the earlier you apply it, the better off you’ll be.
But here’s another thing: The prospectors weren’t looking for copper. They were looking for gold. And without some help, they weren’t ever going to understand what they had actually found.
This last point makes me think that there is something missing in the current Data Mining toolset.
Reductio ad memoria
Over a decade ago, I worked on a project with some truly kick-ass data visualization tools: Silicon Graphic’s MineSet. The project involved showing how a company could mix their own customer data with additional data sourced from a third-party, and throw it into a 3D visualization, allowing variation along five or more axes simultaneously.
For example, in addition to X, Y, and Z axis, we also had color, density, size of the “splat”, and probably some others that I can’t recall. The thrill of taking this 3D model and spinning it around various viewing angles to see correlations between data axes – in real-time, in a web browser! – was, frankly, mind-blowing at the time.
Now, in my opinion the project’s premise was flawed, because the nature of the third-party data didn’t really allow for a 1:1 join with the primary data set – it was more of an exercise in psychohistory.
But the tool was brilliant. It even had an Internet Explorer ActiveX viewer control for browsers.
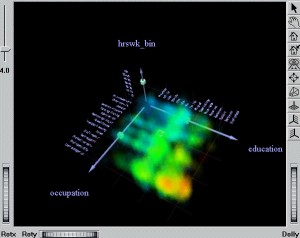
One feature I would have liked to have seen was a “randomize axes” option, where you could cycle through the various available columns in your data set, mapping them to different aspects of the 3D view, and then spin the result around, looking for unexpected relationships.
Because it’s the unexpected that is truly insightful. I want to see the copper pyrites – or whatever else is in there – without having to explicitly test for it.
I don’t think this is Data Mining as it is understood today. But perhaps it might be called “Data Prospecting”.
Finally
A quick web search indicates that, in October 2003, the SGI MineSet product was licensed for development and sale to Purple Insight, a Gloucester, UK-based company that now appears to be defunct. This is a shame, because these visualization tools were unsurpassed by anything I’ve seen to date.
Lisa tells me that some of the underlying algorithms found their way into IBM’s Many Eyes project.
Note: By the way, all of Arthur Ransome‘s books about the young explorers are great, and I highly recommend them, for children of all ages.

Recent Comments