C&L Nicholls - Spacefold Lisa's Page >L<'s Fox Stuff FoxSpoken Volume Index
Lisa Slater Nicholls
download the source
for this session here
As a VFP Developer, you will find plenty of use for XML in the near future. This session will show you why, and how, you'll use it. Here are some general reasons to keep in mind:
As you reflect on the material in this session, you will see many illustrations of these general points although we may not discuss them directly. In this session we'll cover:
This is going to be a long introduction, more like an essay in itself. I’m going to tell you at least one story and give you some background information.
Don’t worry – I promise that the rest of this paper will also have lots of code samples! If you’re already convinced that XML has a place in your future and just want to get started on “how”, you can skip this section. If you’re interested in the “why”, here we go…
A few weeks ago, I mentioned to John Alden that I was doing a lot of XML-centric work these days.
NB: Some of you may remember John Alden from US Fox conferences or from conversations on FoxForum. He is the author of Raven, a fascinating and unusual Visual FoxPro application, of a type generally referred to as an expert system. Raven “learns” and stores complex decision trees created by experts in various fields and then generate recommendations, diagnoses, or other comprehensive results for less-expert users. (If you want to know more, reach John at mailto:alden@tychosoft.com.)
John responded to my e-mail as follows:
[John] XML is where it's at, yet I keep looking for how I might need to use it and not finding much. I'm sure that's because my app is so off the beaten path...
He couldn’t have been more wrong. And, because I’m the person I am, I proceeded to tell him so:
[Lisa] Any app that needs to communicate with other apps (IOW that is not a world unto itself) cannot be so far off the beaten path that XML won't find its way in.
But you have to find that yourself (and you will). There is no point in deciding that it is "where it's at" and just "going there". You will just get there without knowing how it happened, when you need to <s>.
At this point in writing my message to John, I realized that I had an important task in undertaking this topic at the German DevCon this year.
I certainly don’t think you should magically believe that “XML is where it’s at”, no matter where Microsoft or anybody else says you should want to go today. And it’s also true that there are some things you have to experience yourself before they can be meaningful. There is no reason to expect you to derive meaning, or internalize implications, by simply hearing about my experiences.
Still, this session is designed to give you a push in the right direction. I want to let you know why I think XML is so important to your work and how I think you can start using it, now and in the near future, to expand the horizons of VFP applications. I will tell you something about my experiences and extrapolate some general meaning from them, if possible.
Part of the battle has already been won. All of you have written “collaborative software” already. Perhaps you haven’t used DLLs and ActiveX controls explicitly. Maybe you haven’t once exported data to a waiting Excel application or used ODBC to attach to SQL Server or Oracle. You’ve still written collaborative VFP applications.
These days, you are still making use of external components in your VFP applications every time you use GETFILE(). Ā Your VFP app is still dependent on the outside world for help every time you send a REPORT FORM TO PRINT out through the Windows printing subsystem. If your report contains a letterhead image embedded in the FRX, VFP calls the image’s host application when rendering the graphical portions of the page.
All application development environments, including VFP, have weaknesses and limitations. Your users do not accept that as an excuse for limiting functionality, so you write Fox applications that collaborate with other software to get the full job done.
As soon as you write collaborative software, the different components have to talk to each other. XML gives us a way to have a maximum number of components talking to each other with a minimum of fuss.
So… don’t we have COM for this purpose already? Don’t we have established ways to allow applications to communicate? Not really. XML extends your ability to communicate to other environments and applications that do not, or cannot, follow COM rules. Even within a COM-world, XML makes it easier to communicate through firewalls, to transcend configuration hassles, and to alleviate character set and codepage issues. Beyond COM, as you’ll see, the two communicating partners do not have to share much at all.
FoxPro DOS, still great for lots of uses, comes to mind! FPD is not a COM client. But it can parse XML, and it can provide data in XML form. So can almost anything else.
It's true that not even XML is going to spare us from (for example) Fox's non-standard representation of NULLs, or (for instance) vagaries in VB's understanding of arrays. But XML and its sister- and daughter- technologies are better than anything else ever has been at reconciling these, and other, issues.
The people who work on the XML and related standards have a lot of hard-won experience. They are putting it all to good use, designing XML to be both exacting and forgiving, both explicit and inclusive of as-yet-unknown architectures. Just as importantly, these standards are catching on in the real world. All that standards and design work must be paying off! People like using this stuff!
By writing VFP applications that expose XML interfaces, you make your work accessible to more types of developers, who can hook together more types of functionality, than ever before.
As I continued in my message to John:
[Lisa] Before you even get to components... an app like yours has a natural XML tie-in in terms of output. You are writing and preparing output for a completely unknown set of audiences, so you should be preparing it for a completely unknown set of output devices and presentation formats. What do you think is the right way to do that <s>?
And now some people at this conference, those of you who have been reading my essays for several years, immediately know why I am so interested.
Starting in 1997’s Frankfurt sessions, I’ve been talking to you about something called “the one document process". I’ve been looking for ways to make it work, for much longer than that. Lots of other people were searching for ways to make this come true, too, even though they might have called it something else.
In a one document process, we store information only once across an enterprise, no matter how many business units need it, no matter how many formats they want for views and reports, even data input screens. When it comes to the metadata that describes our application, the data that describes our work as developers we also have one document. This one document, or dataset, starts with requirements, goes through testing, and proceeds to end-user help files. We generate the necessary output materials as customized views and formats of one set of metadata.
I don’t mean there is one storage facility for every piece of data (like an Access MDB). I simply mean that data is only stored once, wherever it is stored, and tied together with other data as needed. You don’t write a set of use cases or scenarios for your requirements document, for example, and then have the testers start from scratch to write use cases or scenarios. There is one set of use cases, even though they may look different when the testers use them from their presentation in the requirements document. They may be prioritized differently, or offer different sets of details, in the requirements document and the test plan. The same use cases, again presented differently, help end users understand how the finished application works.
In VFP, we were limited in this goal, partly because our abilities to interchange data and present data were not complete. VFP did not suffice for all input, storage, and output needs; it needed collaboration. For example, we might have Visio diagrams indicating process flow and functionality that were integrated into our metadata describing the application.
We weren’t able to communicate with other components effectively. ODBC, COM, and ADO helped somewhat on the data interchange side but we never really surmounted the limitations of the Report Writer to “speak” properly, or present, the results of our work.
With XML, the one document process for development work finally becomes a reachable goal, without all kinds of kludges. It gives VFP the tool to write once, publish every-where, every-what, and every-how.
Some of you may be wondering, how do all the different views of the single document stay synchronized? For instance, suppose somebody adds a use case late in the development cycle, to match a new requirement. How do you make sure it shows up in the documentation, other than publishing a text file labeled README.TXT?
The answer lies in establishing a “publish and subscribe” system, in which all known consumers of a piece of data register their interest in that data. Typically, the consumers indicate how often they would like to be notified of any changes to the data, and/or receive brief notification of all changes, in a form that allows them to evaluate whether this change is pertinent to their “view” of the data.
Those of you who are interested in design patterns take note: in this system, we have an Observable (the one document data source), and a lot of Observers (the document views). In a typical system, the document object maintains a Changed flag, and also sends out a notifyObservers event to its registered Observers. The notifyObservers event often passes a reference to an object providing details on the typeOfChange.
Any Observer, such as the help file generator system, may choose to re-generate some items on the fly, cache others every time a change is noted, and recreate others only when specified events occur. For example, a list of links on the web in an on-line help file, showing recommended resources, might be sourced “fresh” from the data source every time it is needed, to keep it up to date. Meanwhile, a listing of examples shown in this help file could be cached on the web server, re-generated only when the examples have been changed in some way. The API listing or the table of contents, for this same help file, would only be re-generated when a release version change occurs. The Observable datasource remains unaware of these distinctions, of course.
Rick Strahl is going to show you how all this affects VFP’s ability to function within a distributed application. These days, it’s true, “distributed” often automatically means “working over the Internet”. Some of my examples will have an Internet component or “background”, too.
However, data interchange and data presentation are problems you have to solve whether you work with the Internet or not. My examples and advice are intended to show you how VFP and XML work together within any component enviroment to solve these problems.
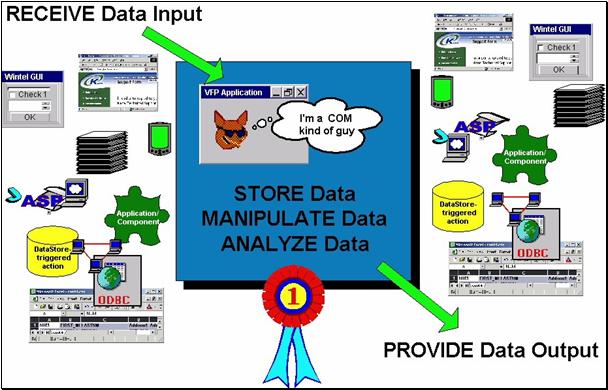
Think about what all your applications do, and by extension what you do every day for a living. They all do pretty much the same thing, even John Alden’s “off the beaten track” Raven (see figure 1 below).
Figure 1, An oversimplified, but comprehensive, view of VFP activity.
Essentially, you receive data input, you take care of it, and you provide data output. VFP is great at doing these things, but that’s all it really does. Looks simple and straightforward, but as you know, the “devil is in the details”.
If the data comes in from an IMPORT process, you have to write certain types of procedures to clean it and import it into your database, error handle, et cetera. If the data comes from a human typist, you have to write entirely different procedures – to validate, provide feedback, and handle any visual cues and infelicities of the GUI controls in your forms and toolbars – to bring essentially the same rows and columns into your database. If your client wishes data to come into the application from a new source – say, a Palm device or a bar code reader – you have to handle different cues, different feedback, a different interface. You will also have to write some code to talk to the Palm device, which is code of a type that VFP is not well prepared to provide.
If your data output or presentation is going to an EXCEL spreadsheet, you may write some automation procedures, whereas you use a REPORT FORM to go to a printer. If you send the data out to a fax, you face a different set of problems once again. When your client says she’d like browser-based reports as well, you go back to the drawing board to start generating HTML in yet another, distinct, output procedure.
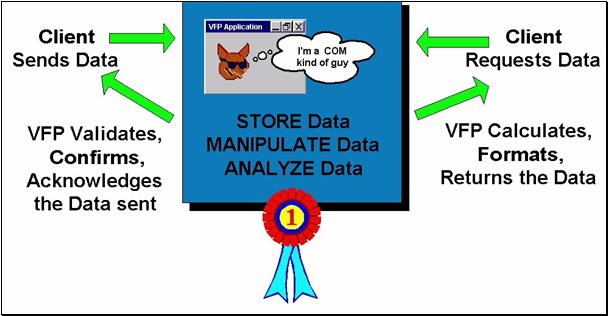
Suppose all these input and output devices could accept and provide the same message format. Each device would still have different limitations and different needs, but the procedures you used to address them all – to provide feedback, to deliver data, to communicate errors – would be the same. In a client-neutral strategy, your application activity and the code you planned to write would be simplified in structure, looking more like figure 2 below.
Figure 2, A “client-neutral” VFP application has a simpler job.
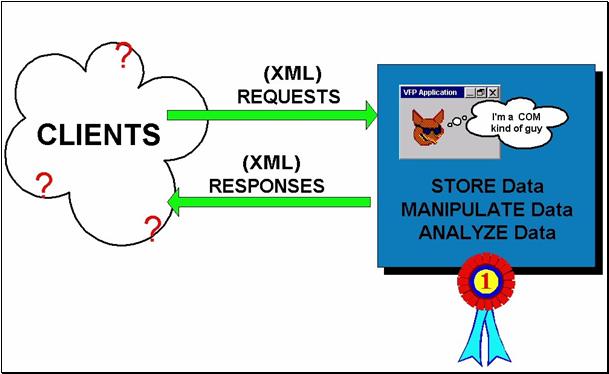
In fact, we could take this a step further and erase the distinction between data input and data output, from the point of view of structuring the code you have to write to collaborate with other applications. Collaboration and messaging between components would be reduced to a series of requests and responses, as you see in figure 3.
Figure 3, A “messaging view”
of VFP applications simply accepts
requests and provides responses, with no distinction
between input and output.
What should the common messaging standard be like? There are several reasons why XML is a good choice for messages between disparate clients and servers. Among them:
With standardized XML requests and responses as your collaboration strategy, you do not plan separately for separate clients. You define the following elements, the same for all clients:
When you see your work put in these terms (a series of uniform requests and responses), it almost looks as though anybody could do database development work! Not so.
Remember that while we’re simplifying the act of collaborating, you still have to distinguish between input and output to perform the actual data work that is the real raison d’Ļtre of a VFP application.Once you receive input data, you have the same storage and manipulation tasks as before.Ā To send the data, you still need to manipulate complex data relationships and calculate results, as before.
We’re just removing the distractions, getting you back to the work you used to do when you wrote FoxPro applications. If you remember, you had plenty of work to do then, and things haven’t changed. Data is still complex, and proper data storage and analysis takes your professional skills. From what I’ve seen in the last couple of years, businesses and organizations of all types sorely need your skills focused on the work of data management, not siphoned off into understanding how a serial port or some other interface to an input or output device can be coaxed to work with VFP.
Suppose your applications currently have a standard Windows GUI interface, do you have to stop using it or change how it works to start providing this common message interface? Suppose your applications currently use REPORT FORMs to provide printed output, do you have to stop? No, of course not.
You define your XML requests and responses based on the kinds of input your applications need, not necessarily to replace them. They can exist in parallel with your current activities, while making room for new clients, without a problem.
For example a database update XML request would include elements currently provided by your data input screen. Your data input screen can continue to function as before, while the other clients used the XML request-processing to handle updates. Whenever you’re ready, you can retrofit the data input “save” button to construct and send the same XML update request to your database procedures as all other clients.
In addition, there may even be some new clients who cannot “speak XML”. For example, the Palm device I mentioned earlier doesn’t yet support WML, the set of XML tags designed as a standard for wireless devices. (The next generation of Palms almost certainly will.) You have two possible resolutions to this problem:
The first strategy, needless to say, is not what I would recommend. It is of limited value, since it fits only one client for only a short period of time.
The second strategy gives you room to handle additional collaborations that are of a non-XML type whenever they come up. You would use this translation and proxy strategy if your customer asked you to handle an EDI exchange. The bulk of your application remains “Palm-“ and “EDI- unaware”.
In our work for Acxiom Corporation, XML has allowed us to be completely “client neutral”. We receive requests, and send out responses to Java clients, Flash clients, VFP clients, VB Script clients, Perl clients, Palm clients… you name it. As described above, we sometimes have to add a thin translation layer when the client doesn’t speak XML natively, but most of the processing continues exactly the same for each request.
Figure 4, Acxiom architecture shows
XML and XSLT
at work both in internal and external exchanges.
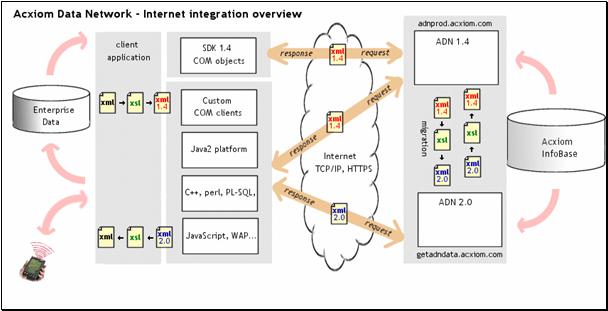
Our XML-handling mid-tier has changed backend data resources, without the client being aware of the difference, more times than you can imagine. These back end data resources are not accessed through the same interfaces or mechanisms -- we have been through ODBC, sockets programming, and CORBA – and they don’t even have the same structures. The client receives the same XML response, all the time, no matter what.
Actually, the client is completely unaware when our mid-tier changes, too. So sometimes the mid-tier includes VFP in the solution and at other times it does not. All I can say is the solutions that include VFP are more robust than the alternatives! Our goal has been to maintain what the client experiences, through each change.
You have probably heard people say that XML doesn’t do much good unless people agree on document formats or DTDs. In fact, this is unnecessary when you add XML’s sister-standard XSLT (eXstensible Stylesheet Language: Transformations) to the processing. As shown in figure 4 above, we have an architecture in which different parts of our own enterprise don’t share the same format, and we use XSLT to move between them. On the client side, our XML-enabled partners have their own requirements for document format, and XSLT comes to the rescue again.
I will talk about the problems that XML and XSLT have allowed Acxiom to solve, with detailed examples, during the session, and the next section will show you all the techniques we use.
First, let’s look at a separate example of a design problem, using something closer to home: the COVERAGE.APP that ships with VFP. It will give you a chance to think about those important definitions I mentioned earlier: what XML document structures will you accept, and provide, as messages? The design possibilities are almost unlimited – certainly less structured than relational database design – so how do you choose?
The COVERAGE.APP provides an example with some unusual aspects, but, at the same time, it’s is an obvious showcase example for VFP-using-XML.
You may recall that, starting in VFP 6, the Coverage log offers a “stack column”, which is not represented in the standard COVERAGE.APP interface or analyzed by the VFP 6 Coverage engine. This omission exists for two reasons:
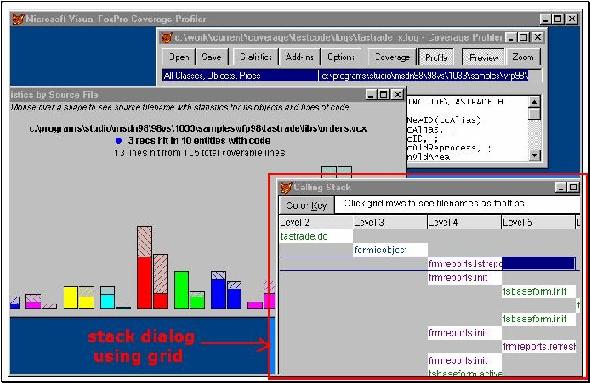
In previous conferences, I have demonstrated ways to include the stack information in the Coverage interface using a separate dialog, since you can add any additional dialogs you want into the standard UI (see figure 5 below). If you were interested in stack levels and not concerning with Coverage and Profiling, you could also build a special Coverage interface on top of the Coverage engine, with this type of dialog as your main display.
As you can probably tell looking at Figure 5, I used a grid to represent the stack information in the Coverage log. Underneath the grid, of course, was a VFP cursor. In the cursor, I added columns as the stack levels grew deeper. With rows representing code components, such as classes and programs, and stack levels represented as columns, each new stack level could be represented in the grid. You simply scrolled far enough to the right or left. I built some extra features, such as tooltips on a cell level, to overlay more information into this interface.
This was convenient – because cursors are natural to us in VFP – but it wasn’t an entirely apt metaphor. Nested levels of programs were awkward to display using this flat structure of rows and columns. Although the grid allowed me to represent the stack, it placed the visual emphasis on the wrong elements. Tracking all program elements that happened to fall in stack level 6, for example, was easy, paging through the grid, but didn’t present meaningful information. I couldn’t turn the row-and-column structure sideways, making stack levels rows and program elements columns, because I’d easily run out of available columns in the cursor.
Attempting to use a relational structure was even worse. Stack levels to code components is actually a many-to-many relationship. This relationship can be modeled relationally, but it does not “feel” natural – nor does such a relationship display “naturally” in a VFP interface.
A tree view might have been more apt as a metaphor, to represent the stack. But it takes one heck of a treeview to display the variety of calls and program elements in any Coverage log. It would have been slow to create, and memory-intensive. What’s more, this representation would not allow me to represent the various statistical elements of the Coverage log entry properly, without a kludge. The display would have been attractive and evoke a stack, visually, but would not have lent itself to statistical analysis.
Figure 5, Coverage VFP6 interface
displays stack levels in a special dialog,
along with other types of display for different purposes.
XML easily solved these problems, and provided a reasonable structure for Coverage stack results. Using Internet Explorer as a default display device – easy to override – provided a simple presentation, and allows the user to collapse and expand the various “limbs” of the stack tree, just as a tree view would, but at far less cost. The XML log also is also economical in its use of disk space. The XML stacklevel document representing a typical TASTRADE.APP run, derived from a Coverage text log of 6 MB, requires about 800k of space.
Our first step, then would be to design an XML document that fit the data properly.
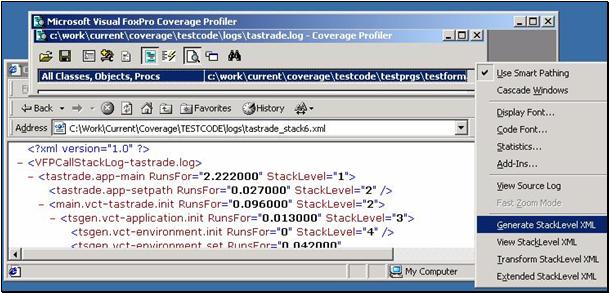
Figure 6, below, shows one of two separate StackXML documents generated by the VFP 7 Coverage engine; the two documents analyze the log slightly differently, but as you can see they are fairly straightforward.
The document level tag shown in the figure is a default version of the tag name. Refer to Appendix B “a sneak preview of new Coverage engine PEMs in VFP7” for list of new properties and methods added to the coverage engine class in VFP7 to support StackXML. This tag name is one of the “tuneable” options available from COV_TUNE.H, as you’ll see in the appendix.
In the “standard” document, shown in figure 6, all calls from one program component on one level will be included from one “root”. For example, if main.prg appears as a stacklevel 1 program, then you will only see one element under the XML document-level element for any successive level 1 main.prg lines in the log. (By “successive” I mean lines in the logs that may be separated by other programs at higher stacklevels, but none at the current stacklevel, 1 in this case.) A stacklevel 1 program with a different name, of course, would have its own tree. Ā This can happen in a log, even at level 1, if you execute various applications from the command window while maintaining a single Coverage log.
If you choose “extended” StackXML, the engine generates a new parent tag whenever the Coverage text log has gone down into the stack, back up to a particular stack level, and then proceeds down again. In this format, main.prg could proceed to several level-2 calls, each of which would have its own tree. When the log next shows a program component at stack level 1, this XML format closes the first stack level 1 tag and opens a new one, whether or not the successive lines at this level were from the same program component.
The “standard” document is more compact and more intuitive if you are looking for an overview of “what calls what”. The “extended” document structure is more accurate, especially if you are doing performance analysis of the separate trees, because it takes into account the fact that the parent program may have been re-invoked, possibly with different parameters, rather than continuing procedurally after the called program returns.
It would have been possible to offer only one base document (the extended one) and then use XSLT transformation to provide the other document on demand. However, providing two base document structures gives each both equal weight as valid base representations.
Figure 6, a sample of Coverage 7 StackXML output.
We don’t ordinarily produce different document structures every time we have a different need. You can think of the Coverage API as allowing you to make two separate requests for two separate data sets, not two representations of the same data, even though they came out of the same log.
When do you provide additional requests and responses, and when do you opt to externally transform a single XML document from one format to another? There is probably no clear-cut line between the two practices that will fit every case. But looking at the data critically and asking “is this a new data set or structure or is this a new representation of the same data?” will help you make the decision.
A third, valid data structure might have separated out the “ON EVENT” lines of code. The Coverage text log doesn’t give you complete information for these lines; you can’t tell what bar or key label was actually invoked. Since these lines can’t be tied to a line of code, they can’t be statistically tallied in the same way. (The standard Coverage interface includes these lines of code as “never marked” or “unmarkable” to make them statisitically netural.) In both the standard and extended StackXML data structures, these lines have “N-A” as the attribute value for their “RunsFor” attribute. This is one way to signify their special status to any code running on this data. However, removing them from the main tree would have been equally valid, and perhaps easier for people doing calculations with this data. XML is flexible enough to handle “inconsistent” or “irregular” data sets – much as the appendices of a book don’t have to use the same format as the rest of the text.
Eventually, you have to arise on one structure that seems appropriate for your data design, and move on.
You’ve decided how your data should be expressed in elements, in this case how the lines of code shown in the text log are arranged and summarized within these XML structures. Even though the structures are more elastic, and the choices more varied, than rows and columns and tables in a relational database, it’s a similar design task. You’ll probably enjoy it.
You can’t use the VFP Database Designer, or other design tools you’re used to, to work out your XML document structures. You need a different IDE.I use XML SPY 3.0, a shareware tool from Icon Information Systems, for my XML and XSL design work. It’s the most flexible of the design surfaces I’ve tried, allowing full validation and intellisense but still providing a “text only” mode when I feel like doing some raw typing. It even incorporates an IE Browser view, so you can see the familiar Internet Explorer collapsible and context-colored version of your document. There’s unlimited undo, a project view, customizable toolbars, and all that good stuff -- but it doesn’t get in my way.Check out http://www.xmlspy.com/default.html.
Now, what about the format of the tags and elements? The Coverage StackXML documents use a fairly straightforward set of tags and attributes (tag names are code elements, attributes give you statistics about each element). No particular standard has been followed here, just a desire for the default display (Internet Explorer’s rendering of the document) to be easy to follow.
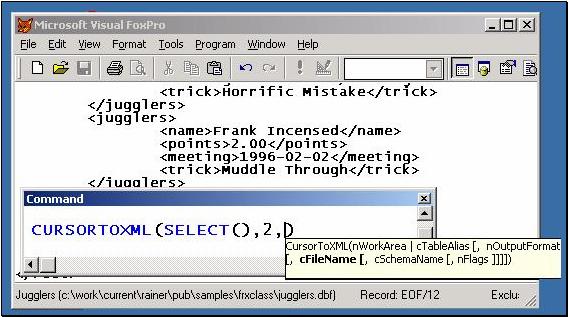
Why not use something like the various XML formats Microsoft makes available for SQL Server, ADO, or Office – each of which, incidentally, can be generated by VFP 7 using the new CURSORTOXML() function ? Attractive as the thought of using the new function is, and flexible as its features are (see figure 7 below), it was impractical to use the actual CURSORTOXML()for the Coverage project for the same reasons that a set of rows and columns doesn’t fit stacklevel data very well: this function emits cursor-shaped, rather than nested-tree-shaped structures. Still, we could have made an attempt to provide a similar-looking structure, in element and attribute names, to make people feel that the StackXML “belonged” to one of the standard structures Microsoft promotes. No such attempt has been made. Why not?
Figure 7, VFP 7’s CURSORTOXML()
function is great for regular,
cursor-shaped data, and gives you lots of good choices
with its arguments and flags.
Here’s why not: this type of consistency is relatively unimportant. You may be raising somebody’s initial comfort level looking at your document because it seems familiar, but you may be making it harder for that same person to actually get work done with your data.
Ā Be as true to the needs of the data, and as clean as possible, when designing your XML formats. You will find that your XML partners use different element and attribute names and styles, no matter what standard you choose (as you see, even Microsoft provides at least three, and other XML-enabled partners will have lots more!). You transform, or map, one way of expressing the data to what your XML partner needs dynamically, using XSLT, whenever necessary.
Let’s face it: the various Microsoft standard XML document formats, and most of the other ones, are fairly ugly and verbose. You’ll also get dragged into religious issues such as “should a document be element-centric or attribute-centric? Most of the time, it doesn’t matter. If you prepare yourself to serve multiple clients and handle any and all standards via XSLT, you can use whatever you want internally. Even participating in a e-Speak or SOAP exchanges, where the broad outlines of the message format are required by the framework, the data interchange portion of that message is up to you.
You will learn design principles for good XML documents the same way you learned good table and database design (only much quicker): by building them and seeing what works efficiently. For example, you will learn not to use attributes for an item that might someday deserve to have a parent relationship with some other data element! It’s practically common sense.
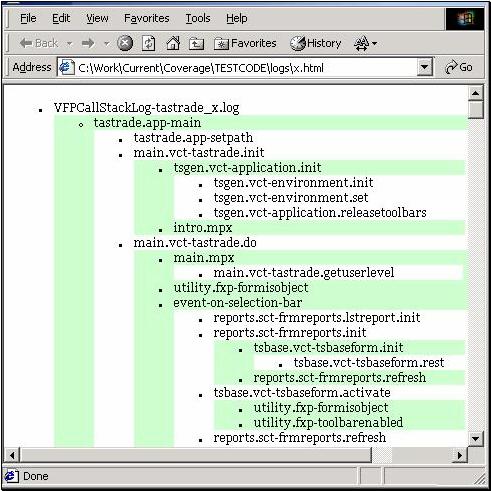
Although the two Coverage StackXML document formats are legible on their own, the VFP 7 Coverage engine recognizes your rights and needs, as a partner in an XML interchange, to have access to transformed versions of these structures.. It gives you a quick way to do the transformation, using the TransformStackXML(tcXSLT, tcXMLIn, tcXMLOut, tlNoShow) method and some related features. This gives you the chance, for example, to display the StackXML as straight HTML in a browser with a “greenbar” style, alternating colors as you move between stack levels, as shown in figure 8. Although figure 8 is an admittedly trivial example of a transformation, this image should help you keep in mind that the presentation of the data is always malleable. This includes its position, its level of aggregation, et cetera. You can, on the fly, decide that whole portions of your data structure are not necessary for a particular transaction (or that a particular customer does not have rights to view all the data). A transformation easily masks these items out of your delivered version of the XML.
Figure 8, an XSLTransformed view of Coverage StackXML.
In the next section, we will go over the technologies we use to perform the major miracles of XML document creation, parsing, and transformation with only minor pain. Before continuing, however, I should mention that there is another HTML-related technology often confused with XSL because of its similar name: CSS.
Although both CSS and XSL technologies are expressed in documents referred to as “stylesheets”, they are in fact very different and complementary in cases where your XSL serves up HTML output. Transform your XSL into HTML or XHTML with class attributes, attach a CSS-type stylesheet reference in the <HEAD> element of your document, and you are all set to change the physical attributes (fonts, colors, etc) of your entire site or browseable document(s) without regenerating all your content.
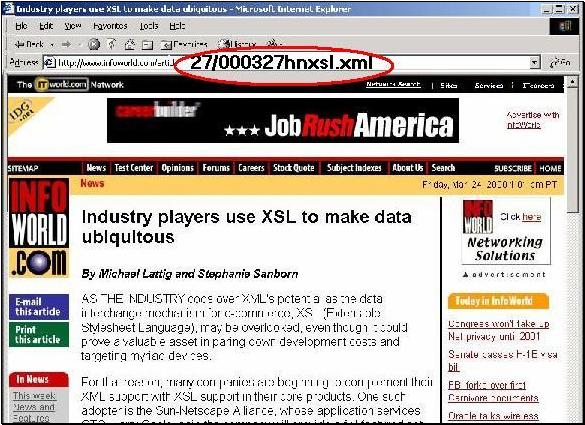
If you want to see a non-trivial example of this strategy at work, look no further than the news articles at http://www.infoworld.com. Notice, in figure 9 below, that the news stories have an XML extension on the filename? Now imagine the database from which the various elements of this page are generated: the banners, the main story in the center, the side panels. Data-oriented people that you are, you can probably figure out the structure of the XML underneath – or at least a workable version of the structure – just by examining this page surface in the screen shot. This content is very definitely created by many tables working together, each with a different structure, each type of element expiring on a different schedule.
The XML document underneath is just the beginning, however. InfoWorld takes that same news story and surrounding content and delivers it in several other forms as well.IfĀ you examine the source, you will just see the HTML end-product of the transform that is appropriate to your client (plus some CSS instructions, if your browser supports it.)
A “smart” pager or other wireless device receives a very tailored version of the same content. A different browser than yours, with different capabilities, probably receives a different transformed HTML version than you see here.
Figure 9, XML at work at InfoWorld’s news site.
Here’s where we start our whirlwind tour of coding XML in VFP. You usually design your document as a DTD or schema (in XML SPY, Visual Notepad, or your own favorite tool), and you put some sample data in it (just as you’d append records interactively in a newly-created Visual FoxPro table, to make sure you had the fields right).
Now we have to figure out how VFP will handle the three main tasks with real documents:
In VFP we are used to creating strings on the fly, and they can be very large strings. There is no reason why you can’t create a couple of classes designed especially for this purpose. In VFP 7, SET TEXTMERGE and TEXT… ENDTEXT have been improved in ways that you’ll find useful for this work. You can also build the document as a string and use StrtoFile(), introduced in VFP 6. If the document is eventually saved to disk, I often use low level file functions rather than SET TEXTMERGE or StrToFile() for the best possible performance.
Most of us started off creating our XML documents in Fox manually, in this manner. I’ll give you some advice, in case you want to do this, and then we’ll go on to some alternatives.
The method you’ll use to build up a document manually varies depending on the content of the document. You’ll often SCAN through tables evaluating the contents of various fields, or include the property values of relevant objects. You will find that the TRANSFORM() method becomes your best friend, because it allows you to convert everything to character type, as you concatenate your string or write out your file, without worrying about the original type of each value.
I’ve created a subclass of my FRXCLASS document generation system, which uses a template FRX to drive report creation. The advantage of this system, which I’ve used previously for WinWord and HTML document creation, is that a single FRX, without any visible objects, can handle grouping and record pointer movement for you, while the events it triggers in the associated FRXClass object creates the real output. The FRX2XML subclass is particularly good in that it generates a default representation of any open file, by default (the other FRXClass subclasses have to know something about your data before they can generate .DOC or .HTM files). FRX2XML creates its default representation of a row using this VFP-native, or “manual”, method:
PROC GenDetailRow() LOCAL liIndex, laElements[1] SCATTER TO laElements FOR liIndex = 1 TO ALEN(laElements) THIS.cXML = THIS.cXML + ; ĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀĀ THIS.XMLNode(FIELD(liIndex),; laElements[liIndex]) ENDFOR ENDPROC
This method is neither a recommendation nor necessarily the best way to create XML that looks like a row available to you in VFP – I’ve done the same task numerous times and keep coming up with different variations. (It never ceases to amaze me how many good ways Fox has of massaging data and text.) I’ve included all the source for FRX2XML, its superclass FRXClass and the other format-specific subclasses of FRXClass, with several examples, as part of the source for this session. You will find a text document named FRXClass.API with full instructions. I find it very convenient to use FRX2XML for various manual parsing situations, including another example application I’ll present later in this paper, and you may too, even though it is just one method of many.
You knew it had to happen. I brought up VFP REPORT FORMs, so we had to discuss at least one bug in the product, FRXs are such a fertile field for them!Be aware that VFP 7 has added a new application-level property, .LanguageOptions, which allows you to specify strict memvar declaration. Unfortunately, there is no way to get the option to give you compile-time errors – you’ll just have to turn .LanguageOptions on and test all your code to see what variables remain undeclared. (Use the Coverage Profiler to help you find code that you haven’t tested!)Even more unfortunately, , at this writing report variables can not be declared so they don’t cause an error when strict memvar declaration is turned on. No word yet on whether this will be fixed before release. The Coverage application saves and restores _VFP.LanguageOptions setting in code surrounding the REPORT FORM command in the DisplayProjectStatistics()method. There is a #DEFINE that will remove this kludge if they fix the bug. If you use use REPORT FORM… NOWAIT, not even this kludge will save you (at least in the current build). Ā You might have to turn _VFP.LanguageOptions off in an early DataEnvironment method, and turn it back on in a late one. I haven’t tried this.
No matter how many times I create a manual XML document creation procedure, however, there are a couple of XML principles I have to keep in mind. You’ll need to follow them, too, for any manual parsing you do.
Here is the most critical rule: be careful, if you build the documents manually in this manner, to make sure your documents are well formed before passing them to another application or a user. An XML document is well-formed if it follows the syntax rules of XML, including the necessity of closing all tags and having a single root node.
NB: The output from an XSL transformation is not required to be well-formed, in that the single document or root node is not required. It is required only to be well-balanced (all the tags that exist have to be closed). This output is considered to be an object of type Document Fragment, not Document, within the standard. These document fragment objects can be concatenated together, or further built up with additional elements using other methods, before being released as a final document object.
Don’t confuse well-formedness with validity. An XML document is not required to have a DTD (document type definition) or a schema. If the document does reference a DTD or schema, it is required to be valid according to that DTD or schema. But every XML document is required to be well-formed, regardless of validity. Although your manual string-building may not be able to tell whether or not a document is well-formed, many of your clients for the document will not be able to use your document at all unless it is well-formed. They are using standard XML parsers to handle the document you send – and the document will not load in the parser if it is not well formed. It is the responsibility of the application formulating the XML to make sure the XML will be parse-able, without any further adjustment, by the receiver of the document.
How can you check for well-formedness? The easiest way to test the XML you’re generating manually is to load your results into a parser conforming to the XML standard, at least for debugging purposes.
To check from the command window, simply CREATEOBJECT(“Microsoft.XMLDOM”), which gives you a reference to the Microsoft XML parser. Now load your document into the parser as a string using the LoadXML(tcString) method, or use the Load(tcFile) method for a file on disk. If the method returns .F. (or errors, depending on your version of the Microsoft parser and/or your version of FoxPro!), you should be able to check the <ParserReference>.parseError.reason property to see what went wrong.
If you don’t mind leaving the VFP environment for your tests, load your XML output into _CLIPTEXT and move over to an XML-oriented IDE like XML Spy. In this type of editor, you will get more exact information about your error, and usually more help in resolving it.
An important error that people often make when creating documents manually is to omit translating characters used in expressing XML syntax when they include data elements. There are only five such characters, but if your data includes them the document will not parse, because the parser won’t be able to tell where tags and entity references begin and end. Here’s how FRX2XML handles the problem:
PROC XMLTransform(tvElement) LOCAL lcElement ĀĀĀĀĀ lcElement = TRANSFORM(tvElement) lcElement = STRTRAN(lcElement, '&', '&' ) lcElement = STRTRAN(lcElement, '<', '<' ) lcElement = STRTRAN(lcElement, '>', '>' ) lcElement = STRTRAN(lcElement, '"', '"' ) lcElement = STRTRAN(lcElement, ['], ''' ) RETURN lcElement
Another way of resolving errors arising from XML control characters in data is to surround the data in a CDATA block, which tells parsers not to parse the contents of the block at all. In this way the offending characters are masked from the parser. I think this is less flexible, however.
Ensuring well-formedness (and validity if your scenario includes a DTD or a schema) is quite a bit of work if you create documents manually. Your alternative in VFP 7 might be to use CURSORTOXML(), which I described earlier, and which removes the problem from your hands. The problem you’ll face, as we saw in the StackXML example, is that the resulting document will be more closely tied to your database structure than might be appropriate for the contents of your data.
A better alternative is to use an XML-standard parser object model to construct, or finish constructing, your document. For document construction, you will usually use the DOM (document object model) parser we’ve already mentioned briefly. In the next section, instead of using the DOM parser just to test well-formedness, we’ll use it for document creation.
The FRX2XML class can just as easily generate its XML using a reference to the DOM parser, as FRX2DOC uses a reference to Word, rather than the manual parsing currently used in this class. It’s too useful a system for me to stop using, even though the mechanics driving each form of output changes over time.FRX2XML is probably the last FRXClass subclass I’ll ever write. That’s because , with XML available, I’m not really interested in getting VFP to generate other formats such as RTF or PDF. I’ll use VFP to generate my XML document structure, and then transform the results using objects and applications expressly written to provide the various output formats, using the principles of XSL:FO (formatting objects). You can check out a commercial XSL rendering engine application at RenderX (http://www.renderx.com/) or FOP, an open source XSL renderer, at http://xml.apache.org/fop/.The XSL:FO standard is, unfortunately, not as far along as the other XML-related standards, possibly because established cross platform alternatives, such as PDF, do exist. This is an area I don’t know much about but will be pursuing in the future.
Return to the parser object reference we used earlier. Because this is an XML-intimate,object, you will immediately see how it protects you from some of the problems you face when you generate documents manually. For example, try this at the command window:
ox = CREATEOBJECT(“Microsoft.XMLDOM”)
oy = ox.createElement("xxx")
oy.text = "<>&'"+["]
? oy.text
* result: <>&'"
? oy.xml
* result: <xxx><>&'"</xxx>
See the difference? The XML for this newly-created element object is appropriately transformed to include the entity references. I have not yet appended this element into an XML document, using the parser – but when I do, this element will load, and become a valid part of a parseable document without any problems.
The DOM has rich syntax for creating nodes of different types and using them to build documents, of which the above is a small sample. The syntax I’m showing you in this section may include some Microsoft extensions, which means that you will not be able to do exactly the same thing with other parsers. Even within the standard, other parsers beyond Microsoft’s may use different method names for the same functionality. Basically, however, they all work the same way.
Here is an excerpt from the VFP 7 Coverage engine’s GetStackXML(tcLog) method, to give you a more extensive example. I’ve added some comments so you can see what the different parser-related activities are:
* instantiate the parser:
loXML = CREATEOBJECT("Microsoft.XMLDom")
* set up a root node, an empty document,
* by loading a string:
loXML.LoadXML("<?xml version='1.0'?>”+ ;
<"+COV_STACKROOT+"-"+JUSTFNAME(THIS.cSourceFile)+"/>")
liStackLevel = 0
SCAN
* I have omitted a section here in which
* the current record is checked to figure out
* whether it is an “ON EVENT” and what its parent node is
IF llAdd
loThisNode = NULL
ĀĀĀĀĀ
IF NOT THIS.lStackXMLExtendedTree
* check to see if this element already exists
* at this level, using an XPATH expression
* This expression can be read “wherethe parent node
* name matches the one I stipulate, the nodename matches
* the one I stipulate, and the stack level is the same
* as the level for the current log entry”
loThisNode = loXML.SelectSingleNode( ;
""+loParent.NodeName+"/"+ ;
lcTag+"[@StackLevel="+TRANSFORM(FStack)+"]")
ENDIF
ĀĀĀĀĀ
IF ISNULL(loThisNode)
* create a node
loThisNode = loXML.createElement(lcTag)
IF llEvent
* set an attribute on the node
loThisNode.setAttribute("RunsFor","N-A")ELSE
ĀĀĀĀĀĀĀĀĀĀĀ
loThisNode.setAttribute("RunsFor",TRANSFORM(FDuration))
ENDIF
* set another attribute
loThisNode.setAttribute("StackLevel",TRANSFORM(FStack))
* add the child node to the parent --
* since the document is “living”, appending the
* child to the parent immediately changes the contents
* of the document XML as a whole:
loParent.appendChild(loThisNode)
ELSE
ĀĀĀĀ ĀĀĀĀ
IF NOT llEvent
* add the current duration statistic
* to the value of the current RunsFor attribute
* for the existing node.Ā Again we use an XPATH
* expression, this time to grab the value of an
* attribute rather than a reference to a node:Ā
loThisNode.SetAttribute("RunsFor",;
ĀĀĀĀĀĀĀĀ
TRANSF(VAL(loThisNode.SelectSingleNode("@RunsFor").nodeValue)+;
FDuration))
ENDIF
ĀĀĀĀĀ ENDIF
ĀĀĀĀĀ
loNode = loThisNode
ENDIFĀĀĀĀĀ
* end of XML-adjusting code, some
* maintenance code here…
ENDSCAN
The code above is not complicated, given a little time spent with an Object Browser and the MSXML parser. The only part that will be strange to you, and take some practice, is the XPATH syntax, used twice in this code snippet. XPATH is a kind of query syntax, which you can use directly in the MS parser to select a single node or value (as used above, with the SelectSingleNode(cXPATHExpression) method) or to get a reference to a collection of nodes sharing some characteristics (use the SelectNodes(cXPATHExpression) method.
XPATH is odd looking but very powerful, something like “regular expression” syntax. In both direct use with a parser, as here, and within an XSL transformation, XPATH allows you to winnow through very complex document structures, using object references and variables, and setting multiple filter conditions on different levels of your query expression. As you can see when you contrast the two uses of XPATH above, you can apply the query expression either to an entire document or the portion of a document represented by a single node reference (which includes all its children).
The DOM syntax and object model has a few other concepts you may find strange at first. For example, it’s often difficult for people to realize that the text surrounded by two element tags (for example the word whatever in the document fragment <mytag>whatever</mytag><someothertag/>) is actually an object, a node of type text, not just a string. Sometimes the Microsoft parser will let you forget about this distinction (other parsers usually won’t) but often you will have to treat this text as the proper text node object type to get the results you want.
Consider the following javascript snippet, which changes the text for a particular element if it has been previously filled, and otherwise just adds new text. If we were editing the document fragment above, this code would change the whatever text to some new text. If <mytag> had no current text, this code would simply add it. In this code you can see how the text is being treated as an object and also how it exists as a child node of another document element:
var oNode = httpXML.selectSingleNode(tcQualifiedNodeName) ;
if (oNode) {
var oTextNode = httpXML.createTextNode(tcNodeValue) ;
if (oNode.hasChildNodes()) {
// we should be at the bottom level
// at this point, in this particular document
// so there should only be one child, the
text node.
// If oNode could have other children, such as
// child elements, I might
// write this code a little differently:
var oOldChild = oNode.firstChild ;
oNode.replaceChild(oTextNode,oOldChild) ;
}
ĀĀ else {
ĀĀĀĀĀ
// no text yet, just add it
oNode.appendChild(oTextNode) ;
}
}
Although using the DOM parser in this manner is powerful and flexible, I recommend you use a combination of VFP’s string-handling abilities and the parser to create your documents. Ā In VFP 7, use the native faciities, such as CURSORTOXML(), too. An especially good technique is to have a skeletal or template document ready, either on disk, in a memo field, or built as a string.YouĀ don’t worry about making sure that this template is well-formed because it is a known part of your system, not something created out of unpredictable parts at runtime. (You checked it for well-formedness when you created it, didn’t you? You won’t need to check it at runtime).
You load this template into the parser and then use a few parser calls to add the dynamic values for this instance of the document using code similar to the javascript above. For example, you could have a request document ready for somebody else’s server that included a complex request format, complete with a number of elements you set the same way every time you make a request of this server. All these options and the general request document would be included in your template. At runtime, you add your user ID and password into the appropriate nodes, add a few request parameters specific to this occasion, and you’re ready to send the request.
If some parts of the request parameters were repetitive (for example, multiple names and addresses), you might have a cursor holding the various instances of the request within one document. You’d use CURSORTOXML() to generate XML for these the sections. There is no reason to have COM calls, building static sections of the document, just for the joy of creating and appending elements to the DOM model!
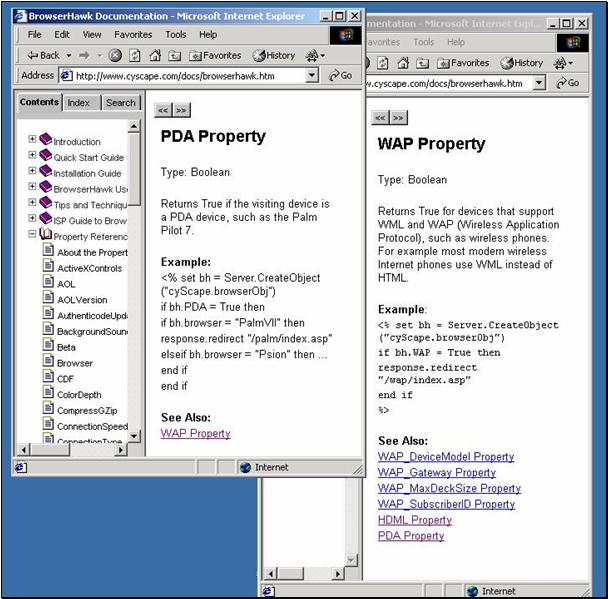
When your application functions as a server, you may want to have many response templates as appropriate to different sorts of clients. (the InfoWorld news article example discussed earlier may be “kickstarted” using this strategy). Web servers can evaluate what type of client has made a request both to determine an appropriate template and the an appropriate XSL transformation to apply.I recommend you check cyScape Products for a look at BrowserHawk (http://www.cyscape.com/products/ ). This product gives you much finer understanding of your client than other web-server-based methods, and also can be used on multiple servers, in multiple environments. The latest version will tell you about the user’s connection speed, available plug-ins, and a lot more – plus it is intelligent about a wide variety of clients (see figure 10 below).
Now that you have some sense of how you construct an XML document, how will you handle the XML documents you receive? The next section will give you some ideas.
Figure 10, BrowserHawk documentation
shows you
how this product can give you critical aid in determining
“who you’re talking to”.
This helps you figure out what type of data interchange
or
presentation is best suited to the current “conversation”.
You can use the DOM parser described above to handle the documents you receive from partners in XML exchanges. Using XPATH query expressions, you can easily grab one or two crucial values from the document, and discard the rest.
Be aware, however, that DOM parsers load documents into memory, so this may not be the best choice for large result sets. This is not a necessary limit of the DOM, it is just a limitation of DOM parsers currently released. (It is easy to imagine a DOM parser swapping parts of a document to and from memory, just as VFP swaps cursors to and from disk depending on their size and available resources.)
Normal VFP string-handling procedures might be more appropriate here, given our ability to handle long strings and less concern with the possibility that you might unwittingly do something “non standard” when you are parsing, rather than creating, a document. You can grab single values with an AT() search, or use low level file functions, MLINE() (don’t forget the performance-enhancing _MLINE offset!) or ALINES() to scan through an entire document efficiently, inserting rows into a cursor as you go.
VFP 7 makes parsing easier than ever, with enhancements to ALINES() and ASCAN() that may be useful to XML development, plus a new STREXTRACT(cString, cBeginDelim [,cEndDelim [,nOccurence, [nFlags]]]) function targeted at XML string handling.
In VFP 7, you might also decide to XSL-transform the document so the result was “cursor-shaped”, matching one of the formats understood by the new XMLToCursor(cExpression|cFile, [cCursorName, [nCursorType | lStructureOnly]]) function. After you ran XMLToCursor on your transformed document, it would be easy to manipulate and store the data using normal VFP methods. This could be a very efficient approach, especially for documents containing multiple rows of results.
There is a second XML standard way of approaching documents, however, beyond the DOM, called SAX (the Simple API for XML). You should consider it for document parsing, ,because it is efficient for large documents.
Until VFP 7 we haven’t had a way to use SAX within VFP. SAX is an event driven model. Your program must instantiate a class that implements the SAX interface – something we couldn’t do until VFP 7. When you tell this “document handler” to parse your document, it triggers the standard SAX events, and the code in your class runs as these events are triggered.
The code you’d write to instantiate the parser and parse the document would look something like this:
LOCAL loReader, loContentHandler, loErrorHandler
loReader = CREATEOBJECT("MSXML2.VBSAXXMLReader")
loContentHandler = CREATEOBJECT("FoxSAXContentHandler")
loErrorHandler = CREATEOBJECT("FoxSAXErrorHandler")
loReader.contentHandler = loContentHandler
loReader.errorHandler = loErrorHandler
loReader.parseURL(GETFILE("XML"))
RETURN
In the code above, FoxSAXContentHandler and FoxSAXErrorHandler are my two classes implementing the standard interfaces. You’ll find my complete example in your source code for this session, as the file MISC\VFPSAX.PRG. As the comments there will tell you, I haven’t been entirely successful with SAX and VFP 7, and I can’t tell whether the problem lies with the VFP beta or the relatively new IVBSAX interfaces I’m trying to use. For the record, I wrote this code just before the September MSXML beta drop came out, and I think they have changed the SAX interfaces considerably in the latest version.
The FoxSAXContentHandler class declaration declares its interface implementation and implements the required class members, in code that looks like this:
DEFINE CLASS FoxSAXContentHandler AS Custom Implements IVBSAXContentHandler IN MSXML3.DLL IVBSAXContentHandler_documentLocator = NULL FUNCTION IVBSAXContentHandler_startElement ( ; strNamespaceURI As String, ; ĀĀĀĀĀĀ strLocalName As String, ; ĀĀĀĀĀĀ strQName As String, ; ĀĀĀĀĀĀ attribs As MSXML2.IVBSAXAttributes) ĀĀĀ ĀLOCAL liIndex ĀĀĀĀ ? "tag: ",strLocalName ? "start text node: " ENDFUNC ĀĀ FUNCTION IVBSAXContentHandler_endElement( ; strNamespaceURI As String, ; ĀĀĀĀĀĀ strLocalName As String, ; ĀĀĀĀĀĀ strQName As String) ĀĀĀĀ ?? " :end text node"ENDFUNC ĀĀ FUNCTION IVBSAXContentHandler_characters(text As String) ?? text ĀĀ ENDFUNC ĀĀ FUNCTION IVBSAXContentHandler_endDocument() ENDFUNC ĀĀ * lots more empty methods here… ENDDEFINE * error handler class is implemented here… * see VFPSAX.PRG.
Note that all required events must be implemented and all required interface members declared, but you don’t have to actually use them all, you can leave a method empty if you don’t need to trigger any code at the event represented by that method.
If you need only a few bits from the center of the document, or if you have to do some calculations based on some parts of the document before you can decide how to treat other parts, SAX is not a good choice. For one thing, you usually can’t guarantee the order of the nodes in an XML document.
But, in other cases, you can see that this approach is quite exciting and has a lot of potential. It is best when your use of the document will work well with a steady , one pass “read” through the entire document, since that is what the SAX parser does.
Once you can create and parse XML documents, you get to the crux of the problem: how do people share these documents? If everybody creates their own internal documents to fit their own processes, as I’ve recommended, what happens then?
Throughout this paper I’ve been saying “you have a document and then you transform it using XSLT to meet somebody else’s needs” or “you receive a document and transform it so it matches your requirements”. What exactly does the transformation do, why do I think it’s a good idea, and how does it work?
The “why” part is probably easiest for me to answer:
The truth is that people will create their own formats, and they will not cooperate on one standard format.There are many reasons for this.Ā But, whatever the reasons, even when you are dealing with simple row-and-column-shaped data, people will not agree on what how that data should be represented.
Oracle will require one root tag and one row structure to do an INSERT into their tables, and their SELECT statement will likewise generate one sort of XML. SQL Server might do something similar, but they will not even use the same format as ADO, let alone Oracle! Siebel will create something called an XML representation of an “business object” (where the “business object” is what VFP programmers think of as an “updateable view”), and this document format will, likewise, be required and nothing like the other two.
So… get used to it. You’re going to use XSLT to map between XML exchange partner formats, even when they are doing exactly the same kind of job (showing rows and columns in a table). When they are doing something more complicated and more specialized than showing rows and columns, the mapping gets a little more complicated to do but it is just as necessary, if not more.
The “what” deserves a paper as long as what I’ve already written (!)… and the “how” might take another paper that long.
I’m going to give you an overview by walking you through an XML exchange process, and then get down to specifics.
The case I’d direct your attention to is the recent partnership between various large airlines, to use XML to solve the problem of ticket transfers. (This story was reported in Computerworld,, 25 September, 2000, “Airlines turn to XML to try to fix e-ticket transfer problems”, by Michael Meehan.) Here’s a statement of the problem and the use of XML to resolve the problem:
Currently, passengers who have electronic tickets have to wait in line to receive a paper ticket from their initial airline if a flight has been canceled and they want to try to switch to another carrier. In addition, airline employees must fill out a handwritten "flight interruption manifest" for each ticketholder who's looking to rebook elsewhere.
But with an industry-standard setup based on XML, Young said, a passenger's electronic ticket could automatically be transferred to another airline's system. The common XML technology would provide an easy-to-process format for all the airlines and could make electronic tickets more valuable than paper ones, he added.
I think all of us can sympathize with the airlines’ desire to better this process, to make the growing numbers of flight cancellations and overbookings easier to handle, for everybody concerned. Let’s walk through what happens now, and what will happen with XML, to see how things are going to work in the new, improved system.
As you see in the quotation above, currently a ticket agent reads an electronic ticket record and either manually or through his/her system translates that e-ticket into a paper ticket. The passenger then takes the paper ticket to another ticket agent in another airline, with whom the passenger hopes to get a seat. The second agent reads the paper ticket and fills out a new record based on the contents of the old one, and issues a new ticket booking the passenger on the second airline.
Here’s the critical bit: the old booking record and the new booking record do not have the same format.The two airlines don’t keep their records the same way.Ā Luckily the agents have read each other’s tickets so many times that the experienced ones are very good at this. They easily transfer the information from the right boxes on one record to the equivalent boxes in the second record. Where necessary, they translate between currencies or timezones or languages, and they squeeze the contents of two boxes together into one field, or break up the contents of one box into two entries, until everything fits their system. (The inexperienced ones tear up three new tickets before they get it right… lines get longer and more flights get missed…)
When you change over this system to XML, the agents no longer have to write out the tickets, which is a good thing. But the two airlines still don’t share the same system (and have no intention of sharing the same record-keeping systems, for many reasons!).
That’s the “why” of XSLT, as you can easily see: it enables one system to be mapped to another. Leaving aside “what” XSLT does to accomplish the translation for a moment, here’s the “how”: a systems developer sits down with one or more experienced agents and learns how these agents convert the contents of one form to the next. Once this process is recorded, no agent ever has to do it again, with five people shouting at them, two new trainees, and somebody’s baggage all over the floor.
The process by which a developer learns a manual system and transfers it to an automatic one should be a familiar process to you. You are all experienced at observing manual procedures and putting them into a program.
The difference between placing a transformation into a program and into an XSLT document is that XSLT is a declarative syntax, not a procedural syntax. You specify what mappings you want to occur, and you can use logic to do so, but you don’t write any code that emits any text. In other words, you don’t write the code that tells the XSLT processor how to do the transformation. In fact, although XSLT processors are based on XML parsers, you aren’t even supposed to think about whether your XSLT processor uses a SAX model parser or a DOM model parser to do its job. The XSLT specifies only the results you want, including any conditional logic, but not how the results are created.
You could, indeed, write DOM handling code or SAX event code to handle the mapping problem instead of using XSLT. But you’d write a lot of code and if even one box on a form or one use of a column changed your logic might be incorrect. In addition, when your disgruntled airline passenger took his paper ticket to a third airline, your logic for handling the mapping between airline 1 and airline 3 would be entirely different.
With XSLT, you don’t change any logic in your program. You don’t recompile anything in your application when changes occur, or when you add another partner to the exchange. You make XSLT stylesheets available, specify which ones go with which translations, and you apply these translations with simple lines of code that do not change. For example, with the Microsoft parser, your code for the transformation might look like this:
oXML = CREATEOBJECT(“Microsoft.XMLDOM”) oXSL = CREATEOBJECT(“Microsoft.XMLDOM”) oXML.LoadXML(cMySourceDocumentAsString) oXSL.Load(cMyXSLTFile) lcResult = oXML.transformNode(oXSL) * If you prefer, you can get an object reference back * from the transformation, rather than a string result, * using .transformNodetoObject method rather than * transformNode().
As you can see above, you have two instances of the Microsoft parser loaded with two XML documents, one the source XML document you wish to transform and the other the stylesheet. Yes, XSLT stylesheets are written in XML. You can manipulate them with the DOM, change parameters in them at runtime using the DOM, like any other XML document.
You may want a quick, command line or Windows shell method of testing transformations, especially if you’re writing your XML and XSL in an editor like Notepad and have no built-in way of associating the transformation and applying it. Here’s a VBS script (which you can also call from a .BAT file using CSHELL.EXE) I use to do this:
'Call it: xslproc.vbs mydoc.xml mysheet.xsl output.htm
Dim XMLDoc
Dim XSLDoc
Set XMLDoc = WScript.CreateObject("MSXML.DOMDocument")
XMLDoc.load WScript.Arguments(0)
Set XSLDoc = WScript.CreateObject("MSXML.DOMDocument")
XSLDoc.load WScript.Arguments(1)
Dim OutFile
Dim FSO
Set FSO = WScript.CreateObject("Scripting.FileSystemObject")
Set OutFile = FSO.CreateTextFile(WScript.Arguments(2))
OutFile.Write XMLDoc.transformNode(XSLDoc)
OutFile.Close
I hesitate to write a lot of XSL examples here, for several reasons. First, the version of the XSLT processors that most of you have available is the one Microsoft published before the standard became available, and has a lot of deficiencies and non-standard syntax.
To make sure that you are writing and testing standard XSL, I suggest you test with at least one parser besides Microsoft’s. My choice is SAXON, written by Michael Kay, one of the authors of the XSLT standard. You can use SAXON on the command line to do transformations. You can download SAXON or “Instant SAXON for Windows”, which is just the interpreter without source, at http://users.iclway.co.uk/mhkay/saxon/ .
If you want to start using XSL with the Microsoft parser, you should download the MSXML Technical Preview from Microsoft’s MSDN site. Their more recent versions are far more standards-compliant than the one they released with IE. Be sure to install the MSXML files in replace mode, following the included instructions, or else remember to switch back and forth between the versions. If you don’t, IE and other default invocations of MSXML will keep using the old version.You can load two separate XSLT transformation engines within the XML SPY interface (use the Edit Settings dialog, on the XSL tab). I usually keep IE loaded along with either SAXON or Oracle’s java-based processor, and I try to make sure my transformations work in both. If I have any doubts, I go with SAXON’s results as indicating a definitive (standards) ruling.
Second, although XSLT is XML, it is extremely unusual looking XML and tends to look quite alarming unless you have a particular goal in mind and can understand the XSLT you’re looking at in relation to that goal. There is no such thing as a “typical” translation document, in my experience. I’ve included one short and somewhat frivolous example of XSLT in the sample application I discuss in the next section (you’ll find it in the ASP\SUPPORT directory of the source for this session). Time permitting, we will go over several examples of non-trival XSLT syntax in detail during the session.
As part of your session notes, in the \ASP directories, I’ve included a tiny but complete ASP application, using a VFP COM component where some data manipulation takes place. This COM server, which you’ll find supplied with all source in the \COM directory, is basically an “all purpose” VFP server that exposes the Application property and its crucial methods. In this version, a subclass augments the base DataToClip method to be able to provide XML along with its standard data formats. I use an instance of FRX2XML to create the XML within this augmented method.
Don’t be too concerned about the fact that it is an ASP application, because it is the structure of this application rather than its environment that should drive home the point I wanted to make. The COM component represents “the stuff that VFP does really well” and that we want to pass in to VFP to do. Although my little all-purpose VFP server won’t be anything like your implementation of the real life component it represents, keep in mind that a minimum of COM calls is a good idea, whether the caller is a web server or not. Replace this VFP component with some VFP component that accepts and returns XML instructions, and you’ve got it.
The external part of this application, here written in VBScript-ASP, represents “the stuff that is required for an XML-enabled application”. Some of it might be done in VFP in your case, rather than externally as I show here, but I wanted to make sure you could see all the XML-related pieces spread out in script code, while the “standard” VFP processing parts remained hidden behind the COM object.
What are the external pieces?
LSN_XML.TXT describes each file, in all the source directories, individually, so I’ll just quote from the relevant section of that text file here:
That’s it. You have configuration options, you have localization message strings, you have some standard chores such as figuring out what transforms are appropriate to your current action and current options, and actually performing the transformation, you have a set of XSL files, and you have a “face” of the application, some “main” routine, which accepts requests from the outside and returns responses to the outside.
As far as I am concerned, most, if not all, of these exposed pieces can be done in VFP rather than externally as shown here.You might certainly decide to instantiate your DOM parser objects and do the transforms within the VFP component.Ā You could evaluate which XSLT transforms are appropriate for the current action, either inside or outside the VFP component. In this case, the deciding factor probably will be: Where can you best cache objects that do the work, even if they would the same objects (in this case, MSXML parser instances) in each implementation?
This example happens to be about ASP, and hence a web server handling the XML exchange, although once again you shouldn’t assume that this sort of exchange is only “important” over the Internet.Within the Internet space, I just want to point out that there are additional differences of opinion about “where some of the work should be done”, beyond the server-side application portioning we’re discussion here..Ā The division of labor to be performed isn’t only “which application component on the server does what job”, it’s also “what does the client do versus what do the various serving tiers do”.Microsoft, as usual in favor of relatively heavy clients, often indicates that you should hand over a reference to the XSL spreadsheet within the body of the XML document and then send that document to the client, so that the client can do the transform. I disagree. They like this approach because it lessens the burden on the server, but it also assumes a level of familiarity with XSL and a capability on the part of the client that is not a wise assumption (unless you want everybody in the world using IE as a client <g>!). It is much better, in my opinion, to do the transform on the server where you have control over it and so that you can serve all potential clients equally well. You can do the transform efficiently to maximize server performance – this is like anything else.
The important thing you should notice, when reviewing this application, is how little of it there is. It’s just a thin shell around the work you already know and do well (represented by the “VFPAllPurpose” server in this implementation).
Among these external pieces, you’ve also already seen that some work can be done by native VFP code, such as string manipulation, as well as by COM components designed expressly to work with XML. Your goals should be to use each tool where it is optimizable. For example, your VFP code can sort and calculate output before translating that output to its XML response format. You could also go to the XML response format and then ask your XSLT transformation to handle the sorting and calculating chores – but VFP will do it faster. (XSLT even has indexing and lookup capabilities – but whose version of these features do you think you should use?) On the other hand, when you’re ready to prepare an HTML version of your XML response, this is something XSLT handles far more elegantly than you will in FoxPro code, in my opinion.
One other criterion you might want to use when deciding which components do the work: What do you know well, what do you not know well? ĀĀ The answer to this doesn’t always point in the same direction that you might think.Because you know FoxPro well, and you do not know the DOM well, you might expect me to recommend manual document creation using VFP code.Ā However, as you’ve seen, I recommend you let the parser take care of document manipulation to avoid errors, even though it means you have to learn parser syntax.
The parser knows what a valid document and a well-formed document look like, better than your code, and will not make mistakes. The goal of delivering valid and well-formed XML as your application’s responses is so crucial to an XML-enabled application that this is my highest concern. It’s this goal, faithfully pursued, that makes everything else run smoothly.
I started this paper with a bow to my friend John Alden, and I’ll close it by fulfilling a promise to mention another friend, Kevin Jamieson. Kevin is a young, but happily shining IT professional. I’ve known him since he and my son Josh were 5 years old and, when he asks a question, it’s generally a good one.
Kevin has become something of a Luddite, even though he works with high tech equipment all day. He has bought a manual typewriter to record his important (trans: non-work) thoughts. He asked me to ask, and think about, “why anybody would ever type XML on a typewriter”. Kevin says if XML were really good we’d want it everywhere.
I promised I would record Kevin’s question in this paper. I don’t really have an answer for you, or for him, about why we’d type XML on a typewriter.Unlike Kevin’s physicalĀ journal pages, XML isn’t really a product or an end result, in itself. It just provides a conduit – both for data exchange and data presentation – to more products and end results than anything else I can imagine. Since it’s not an end product, since it requires some application or device to extract meaning from it and apply format to it… it’s hard to imagine XML existing outside the world of electronic devices and processing power.
But, within that world, it has so much to offer! I expect, for as long as I work with computers in the future, I’ll be working with XML. When I’m using VFP to extract the meaning and apply the format to XML, I know I’m working with two well-matched technologies, and one of the most creative partnerships that the world of computers can offer any developer today.
Colin and I have been using a strategy that seems to work very well for different types of clients: we design our applications as out-of-process (EXE) COM objects, but also give them a command-line usage. This strategy does not have to be adjusted or re-implemented for each application. For example, we typically allow only one command line argument, and it always does the same thing.
The command line argument is a filename. We stipulate that the format of this file is a set of lines in the format property = value. The main program associated with EXE does the following:
Internally, the .LoadFile method simply validates the filename and converts the contents of a file to a string, which it sends to a .LoadString method.
The .LoadString method goes line by line (normalizing whitespace, and using CRs, CRLFs, or LFs as line terminators) through the string:
One beauty of this system is that the .Run, .LoadString, and .LoadFile methods are also available to the COM object. By calling.LoadFile or .LoadString – whichever suits you – followed by .Run, a COM client can make efficient use of a VFP server, with the fewest possible number of COM calls. This is great for performance reasons as well as giving consistent functionality between your command-line and COM clients.
We find that some early binding versus late binding COM clients have different needs with regard to passing Fox parameters. Some client environments must pass the arguments (no argument can be optional), others have difficulty with methods that require arguments (all arguments must be optional).
With strong typing in VFP 7, this problem may be somewhat alleviated. To date, however, to serve these differently-abled clients equally, we usually have something like a .cParameter property. If an exposed method such as .LoadString expects an argument and does not receive it, it looks to this property for an alternate source of the required information. A client that has trouble passing VFP parameters uses this property.
Although it is true that not every system has a single process easily defined, to be invoked by a .Run or .Execute call,this is usually solved withĀ an “action” property the client can set, like any other, in the set of properties processed by .LoadString.
I highly recommend this practice. I guess it has nothing explicitly to do with XML, on the face of it! However, it is all part of giving equal access to different types of clients, creates efficient COM applications, and works very well with XML-enabled applications in general.
Stack XML enhancements to Coverage in VFP7 include the following new PEMs for the cov_engine class in COVERAGE.VCX. They are shown here with the PEM descriptions added to each member as part of the VCX, with a little extra explanation in some cases. Note: cov_standard (the interface class) was not touched in this enhancement.
| .cSavedStackXML |
Holds the name of the saved Coverage stacklevel analysis in XML form, after this file has been saved to disk. Set back to default ("") when you load a new log. |
| .lStackXMLExtendedTree |
If .T., generates more extensive StackXML, so Profiling of each branch can assess effects of args and other factors for different invocations of a module. Defaults to .F. but if COV_LOAD_STACK_FROM_DBF is .T., this more extensive XML is always gen'd. |
| .ShowStackXML(tcLog) |
Calls
GetStackXML(tcLog) and DisplayStackXML(tcXMLFile)
to run coverage analysis figures against
a specific VFP project set of files. tcLog
argument ignored if DEFINEd COV_LOAD_STACK_FROM_DBF
is .T. Returns .T. if successful. |
| .GetStackXML(tcLog) |
Generates
Stack Analysis XML from tcLog, defaulting
to current Coverage source log. tcLog argument
ignored if DEFINEd COV_LOAD_STACK_FROM_DBF
is .T. Returns .T. if successful. |
| .DisplayStackXML(tcXMLFile) |
Displays
XML file, defaulting to the current Stack
Analysis filename indicated by the cSavedStackXML
property. Returns .T. if no error occurs. |
| .ToggleStackXMLExtendedTree() |
Toggles
.lStackXMLExtendedTree. Designed to be augmented
in subclasses to reflect this switch in
the UI, change default XSLT on this basis,
etc. Returns .T. if no error occurs. |
| .cStackXSLT |
Holds filename providing default XSL Transformation stylesheet to be applied by default to the generated Stack XML analysis document, when TransformStackXML is called. |
| .TransformStackXML(tcXSLT, tcXMLIn, tcXMLOut, tlNoShow) |
Applies tcXSLT (default to .cStackXSLT) to tcXMLIn (default .cSavedStackXML, GetStackXML called if empty). Saves result to tcXMLOut (defaults to tcXMLIn-based generated name w/ HTM ext). If ! tlNoShow, calls DisplayStackXML. Returns .T. if successful. |
Additional Coverage changes in VFP 7 not shown here to support this enhancement include various existing methods updated to account for the new Stack piece.For example,Ā cov_engine.Init(..) has been adjusted to call GetStackXML() if the engine is instantiated in unattended mode, along with creating and saving the target dbf and skipped files dbf.
Interface changes in the COV_OPTIONSDIALOG class (see figure) and COV_LOCS.H localization message file as well as the shortcut menu expose the Stack features.
New bottom section of Coverage Options dialog allows you to set Stack options and defaults.
New tune-able options in COV_TUNE.H to support the
Stack feature include the following: