Say you have a data model that looks like this:
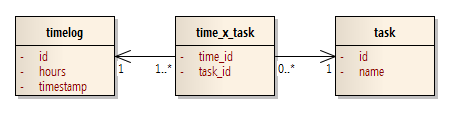
In other words, time entries can be tagged against multiple tasks. (I know this seems wrong, but trust me, it made sense in the context of the system.)
The problem we had was that the complicated query behind the report of “total hours by task” was counting the hours twice or more, for any entry tagged to more than one task.
[code:c#]select T.NAME, sum(L.HOURS)
from time_x_task X
join timelog L on L.ID=X.TIME_ID
join task T on T.ID=X.TASK_ID
group by T.NAME; [/code]
After thinking about how I could alter the query so that each timelog.HOURS was included only once in the SUM(), it occurred to me that it might be better to just distribute the hours across the tasks:
[code:c#]select L.ID, T.NAME, L.HOURS, L2.cnt, (L.HOURS/L2.CNT) as ACTUAL_HRS
from time_x_task X
join task T on T.ID=X.TASK_ID
join timelog L on L.ID=X.TIME_ID
join (select count(1) as CNT, TIME_ID
from time_x_task
group by TIME_ID) L2 on L2.TIME_ID=L.ID;[/code]
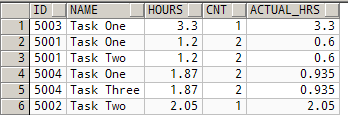
Now we SUM(ACTUAL_HRS) instead of sum(HOURS).
OK, this is a contrived example, but the point I’m trying to make is that sometimes you have to throw away the original question and think about what you’re really trying to achieve.
Leave a Reply
You must be logged in to post a comment.